A Network Architecture Example: The WWW
- The World Wide Web is the Biggest Thing in computer networking. It
provides (for the first time) an information model to support browsing
on the Internet.
- A browser, or viewer program such as
Netscape
or Internet Explorer
is used to fetch and display "pages" of information from a server. A page is
simply an ASCII text file, written using a simple markup language called
HTML.
- You should already be aware of the WWW as a source of information,
particularly its use as a distribution medium for subject material at Bendigo.
Uniform Resource Locators - URLs
The URL or "hyperlink" is the basis of the WWW. A URL defines the
location of a WWW page in the following way:

When a user clicks on a highlighted hyperlink within a WWW page, the
user's browser uses the information in the associated URL to obtain
and display the desired page
Connection Establishment
To fetch a WWW page, the browser application program (or more correctly,
process) running on your local computer first establishes a
connection to the remote host.
What this means is that the browser process uses the facilities of the
network connecting the two computers to send a "connection request"
message to a server program (process) running on the computer whose name
was given in the URL.
If the remote server process is prepared to accept the connection, it
responds with a "connection accepted" message.
Note that we are, for the moment, ignoring the process of "looking up"
the remote host -- discovering the network address associated with its
domain name.
The HTTP Protocol
Once the two application processes have an established connection
between them, they can communicate reliably.
The browser then sends a request, in ordinary plain text, to the server
thus:
GET /home.html
The string "GET something" is one of many commands defined in
the Hypertext Transfer Protocol, HTTP. The server responds by returning
the contents of the file /home.html, also in ordinary plain
(ASCII) text.
Finally, the browser process interprets the HTML markup in the returned
file, and displays it to the user.
Connections Revisited: Transport Service
The "connection" used in transferring data is normally implemented in a
software module in the operating system of each of the computers
involved in the transfer.
This module provides a (so-called) transport service to processes. The
transport service module is responsible for breaking an incoming stream
of data into chunks (or, more correctly, Transport Protocol Data Units
or segments) for transfer across the network Each segment is prefixed
with a transport header, to indicate to the remote transport service
module what data it contains, and to carry other communications-related
information.
As each segment is received from the network, an acknowledgement is
sent back, so that damaged or lost segments can be resent, ensuring
reliable communications. The transport protocol defines the rules by
which this is achieved.
Note that the need for reliable interprocess communications is
independent of the nature of the application (in our example, the WWW),
hence this service can be shared by many different applications which
need reliable data transfer across the network.
In the Internet, the reliable transport service module implements the
TCP protocol.
Packet Delivery: The Network Service
Once the transport module has built a segment of data, it passes it to a
network service module, also normally residing within the operating system.
The network service module builds a packet containing the entire TPDU as
its data part, and prefixes a network header containing, among other
information, the network address of the destination computer. It then
passes the packet to the actual network for delivery.
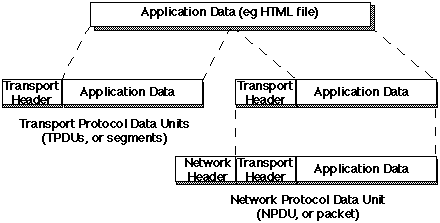
In the Internet, the network service module implements the IP protocol,
and NPDUs are normally called IP packets.
Note that the network service need not guarantee reliable delivery of
packets - why not?
A Communications Layered Architecture
A conceptual, or abstract, representation of this system looks like:
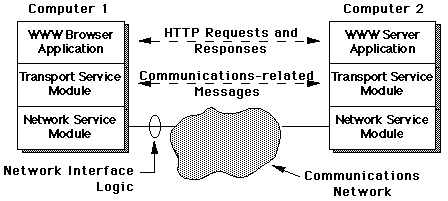
Notes:
- The flow of actual data is from one WWW application (eg, the
server), down the "stack", across the network and back up to the other
WWW application - see later
- The apparent flow of data in the upper layers is peer to peer across
the network
- The operation of the application processes is independent of the
underlying communications and network module technologies Đ- hence a
communications architecture.
Addressing
Two levels of addressing are required to specify the particular remote
application process to which data must be forwarded:
- A network address of the remote system - typically this is given as
a system name (such as ironbark or www.bendigo.latrobe.edu.au) which is mapped to a numeric
address in the network access layer. The address is contained in the
NPDU header, and defines a system's point of interconnection to the
network.
- An address within the remote system which identifies the particular
application process to which this data is to be delivered Đ this is
called a Transport Service Access Point (or TSAP).

This lecture is available in PostScript format.
The tutorial for this lecture is Tutorial #01.
[Previous Lecture]
[Lecture Index]
[Next Lecture]
Phil Scott