GET http://www.bendigo.latrobe.edu.au/index.html HTTP/1.1
GET request looks like:
The response from the server consists of a status line, then a number of plain text headers, followed by a blank line and then the requested data object. It's clearly a very similar format to an RFC822 email message:GET /index.html HTTP/1.0<newline><newline>
GET /index.html HTTP/1.0
HTTP/1.0 200 OK
Server: Netscape-Enterprise/3.5.1C
Date: Tue, 20 Mar 2001 11:48:39 GMT
Content-type: text/html
Last-modified: Fri, 16 Mar 2001 02:22:52 GMT
Content-length: 11378
<!doctype html public "-//w3c//dtd html 4.0 transitional//en">
<html>
<head>
........(etc)
HTTP/1.0 200 OK
Server: Netscape-Enterprise/3.5.1CDate: Tue, 20 Mar 2001 11:48:39 GMTLast-modified: Fri, 16 Mar 2001 02:22:52 GMT
Last-modified:" header can be quite useful,
see the HTTP/1.0 "HEAD"
request, later.
Content-length: 11378Content-type: text/html
Content-Encoding:" (used in
MIME-encoded email messages) is not normally used in HTTP
because the protocol is designed to handle "8-bit" data. That is,
any data at all can be sent after the blank line which signifies
the end of the response headers.
GET RequestGET request (and other HTTP
request types, see later) to additionally send
a series of optional Request Headers along with the
request. For example, here's a typical request to ironbark, snarfed
from the local network:
The request headers are terminated with a blank line -- hence the need for two newlines, as seen in the first slide of today's lecture. It's also possible for the request to contain a "message body", just like a response message -- we defer discussion of this until later in the unit.GET /index.html HTTP/1.0 User-Agent: Mozilla/3.0 (X11; IRIX 5.3 IP12) Host: ironbark.bendigo.latrobe.edu.au Accept: image/gif, image/jpeg, */* Referer: http://ironbark.bendigo.latrobe.edu.au/index.html
Perhaps the most interesting optional request header is
"If-modified-since:", which takes an HTTP standard
GMT time/date string as its value. If the requested page has not, in
fact, been modified in the specified period, it won't be returned --
instead, a "304 Not Modified" response is sent.
This is called a Conditional-GET and is very useful in
support of caching, of which more later.
<img ...>
images, HTTP/1.0 must open a total of 11 TCP connections -- one for
the original page, and 10 for the images. Problems which arise from
this include:
To implement Persisent Connections, HTTP/1.1
introduced a new request (and also response) header called
"Connection:". This can take two values:
"close" (which means that this is
not a persistent connection) and
"keep-alive", which means that the TCP connection is
held until either side sends a
"Connection: close" header, indicating that it
wishes to terminate.
The browser can utilise a persistent connection by sending multiple
requests over the connection without stopping and waiting for each them
to be satisfied before sending the next -- the reponses are "in the
pipeline". Similarly, the server can respond with responses sent one
after another another. This is possible because each request can be
unambiguously identified, as can the responses, using the
"Content-length:" headers. The huge wins here,
obviously, are that there's no delay opening multiple TCP connections,
and the slow-start algorithm has time to get up to full speed.
The Conditional-GET operation seen earlier allows support for caching at the browser level -- that is, the browser can keep a local copy of an object and check if it's up to date before displaying it.
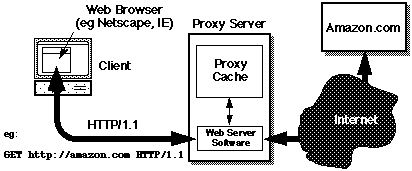
HTTP/1.1 adds support for proxy server caches. A proxy
server is an HTTP server which fetches Web objects (pages, images, etc)
on behalf of its clients. Requested objects are always specified as
full URLs in HTTP/1.1, so the first line of a GET
request now looks like:
GET http://www.bendigo.latrobe.edu.au/index.html HTTP/1.1
Expires: Tue, 20 Mar 2001 02:22:52 GMTPragma: no-cache
Etag: "8802-2c72-3ab178fc"If-None-Match: "8802-2c72-3ab178fc"You can discover lots more about HTTP at: http://www.w3.org/pub/WWW/Protocols/Specs.html
 [Previous Lecture]
[Lecture Index]
[Next Lecture]
[Previous Lecture]
[Lecture Index]
[Next Lecture]