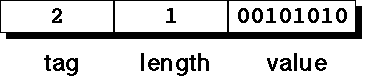The TAG is (usually) encoded in a single octet, containing its value (see earlier) in binary in the low-order 5 bits and some other information in the remaining 3 bits[1].
The LENGTH can be encoded in two possible ways, definite (which usually only requires a single octet, and is the most common) and indefinite (which requires, at least, several more octets).
The VALUE field is encoded using a specified method which is
appropriate to its type - for example, an INTEGER
is sent as its binary 2's complement equivalent; an OCTET
STRING is simply the appropriate octets.
[1] The CLASS (see slide 4) of the object (most significant 2 bits), and whether it is a simple or constructed (structured) data type (1 bit: 0 for simple, 1 for constructed).
A small-valued integer might be encoded as: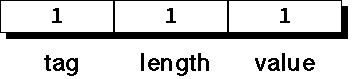
An octet-string encodes just the bytes of the string, thus:
- Note that the value field is encoded using 2's complement notation
- If the value is greater than 127 or less than -128, more octets are required, hence the length is greater.
OBJECT IDENTIFIER data type. An
OBJECT IDENTIFIER is a simple
ASN.1 data type with special properties.
An OBJECT IDENTIFIER is a data type denoting an
authoritatively named object, regardless of the
type of the object which it names. The (somewhat
hubristic) notion here is that provides a naming
scheme allowing us to specify names of
things, in a global sense, such that everything that there
is in the universe[2] can have a
globally-unique name.
It is written as a sequence of non-negative integer values which
describe a traversal of a tree. The tree consists of a root connected
to a number of labelled nodes via edges. Each label
consists of a non-negative integer value and an optional brief textual
description (or Object Descriptor associated with
it). The most common format for writing down the value of an
OBJECT IDENTIFIER is as a dotted sequence, thus:
This identifies the object found by starting at the root, moving to the node with label 1, then moving to the node with label 0, and so on. The node found after traversing this list is the one being identified. Other formats for describing OBJECT IDENTIFIERS are also used, see later.1.0.8571.5.1
[2] More correctly, we should probably say every kind of thing in the universe has a unique name, instead of "every thing".
OBJECT
IDENTIFIER, its associated Object
Descriptor, the INTEGER and the
OCTET STRINGSNMP additionally defines some new data types for use in the management framework:
IpAddress
IpAddress ::=
[APPLICATION 0]
IMPLICIT OCTET STRING (SIZE (4))
Counter ::=
[APPLICATION 1]
IMPLICIT INTEGER (0..4292967295)
Gauge ::=
[APPLICATION 2]
IMPLICIT INTEGER (0..4292967295)
Thus the "TCP" subtree of object identifiers in the MIB starts with the prefix (OBJECT IDENTIFIER):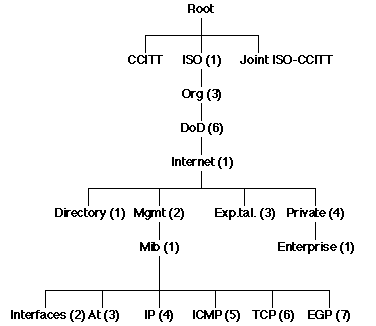
whilst the "System" subtree starts at:1.3.6.1.2.1.6
This could also be written as:1.3.6.1.2.1.1
{ iso org dod internet mgmt mib system }
or in a "hybrid" format:
{ iso(1) org dod 1 mgmt(2) mib 1 }
system OBJECT IDENTIFIER ::= { mib 1 }")
of the MIB is: "{ system 1 }", or
The following is copied from the generic MIB description commonly found in the file "1.3.6.1.2.1.1.1
/etc/mib.txt" on Unix systems, and is
the ASN.1 definition for this same MIB object:
sysDescr OBJECT-TYPE
SYNTAX OCTET STRING
ACCESS read-only
STATUS mandatory
::= { system 1 }
NB: The value of the SNMP type (variable?)
"sysDescr" is a string of text which gives the
manufacturer's type designation of the managed device, and commonly
some other interesting facts such as firmware version numbers and build
dates. Note that the abbreviation
"{ system 1 }" is commonly allowed
by SNMP software, since the OID path to the MIB is normally assumed.
 [Previous Lecture]
[Lecture Index]
[Next Lecture]
[Previous Lecture]
[Lecture Index]
[Next Lecture]