Subjects ->
Computer Networks ->
Lectures ->
Lecture #8
Lecture 8: Web Commerce Technologies
Server-Side Programming and Web Commerce
FORM-based Web pages and Web "server-side" programming are the key
enabling technologies for Web Commerce. The most
common server-side programming technology has been the Common
Gateway interface (CGI), commonly using the Perl programming
language, but this is gradually changing.
Web sites can sell either tangible goods (merchandise)
or content. Important issues include:
- Marketing
- getting customers to your site, and
presenting and selling your product, ultimately convincing them to
order something.
- Ordering
- typically managed by a
shopping cart application, see next
slide.
- Order Processing
- check order, verify payment,
address, etc. Possibly send customer email confirmation.
- Order Fulfilment
- packaging, shipping, etc
Shopping Carts
A shopping cart application is a server-side dynamically
generated set of Web
pages which allow a user to browse items, and add them to their "cart"
at the click of a button.
The user can (usually) examine and modify the contents of their "cart".
When they are ready, they move to a final "commit" page, where they
finalise the ordering process, with (for example) a credit card number,
shipping address and an email contact address.
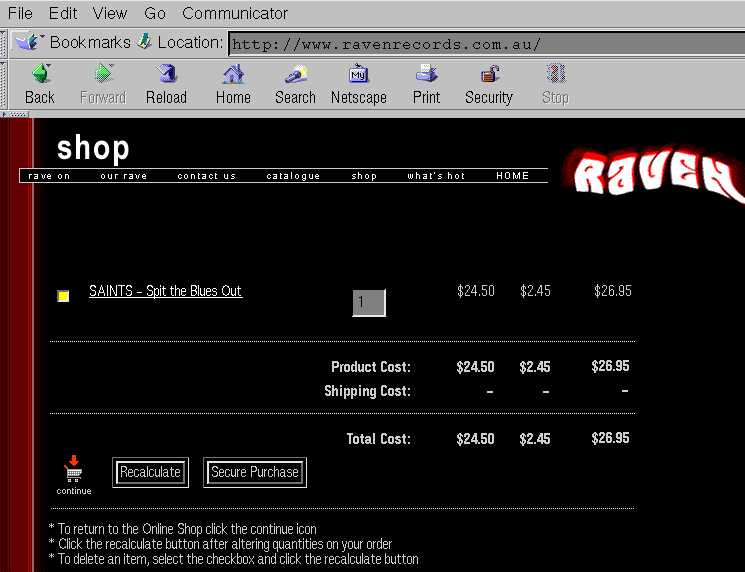
Image used with permission of
Raven
Records, the "THE ULTIMATE IN REISSUES".
Maintaining State -- Session Management
A shopping cart application is more difficult to implement than it may
seem. Because the HTTP protocol is stateless, a Web
server regards every connection as entirely new, with no relationship
to any previous or future connections.
Most modern Web Commerce sites use the concept of a Web
session -- a series of Web requests and responses
linked together by a state variable called a session
identifier. A first visit to the sites "home page" creates a
new session, and the HTTP response is associated with a new session
identifier, or SID. All subsequent transactions are somehow labelled
with the same SID.
- The session identifier is commonly a (very) large random number
and/or text string possibly combined with a (hashed) combination of
the some other client information -- maybe the IP address of the
client.
- Session management can be rather messy on the server, since
information must be maintained about all "current" sessions, and
decisions must be made as to the deletion of "expired" sessions.
There are three Web technologies availabe to support session
management: Hidden Fields, Cookies and URL-embedded Information. Modern
practice is to use a "belt-and-braces" approach, incorporating all
three.
Hidden Fields
A hidden field within an HTML form is the simplest way
to do session management. A hidden field is like any other
INPUT FORM entity; it is simply not displayed by
the browser. It can be inspected using, for example, the "View Source"
option of the browser, where it will look something like:
<input type="hidden" name="SID" value="XYZZY8765765vk5ht">.
- Submission of this FORM to the specified server will contain the
name=value pair from the hidden field along with the data from any
other (non-empty)
INPUT elements.
- The server-side program which processes the FORM at the server will
normally return the same hidden field back to the browser.
Whilst hidden fields are a simple technique for state maintenance, they
are not a general solution, since they only work in the context of a
sequence of FORM submissions. For more generic applications, another
technology is needed.
Cookies
A cookie
is a small "piece" of information (in fact, a string of characters)
which a server can store "within" a Web browser. For example, the
following response header (sent in addition to any other HTTP response
headers) "sets" a cookie in the
user's browser:
HTTP/1.1 200 OK
Set-cookie: SID=XYZZY8765765vk5ht
...other response headers
All subsequent accesses to the same server (and by the default, the
same response entity that generated the cookie) will include the
cookie sent as the value of an additional request header, eg:
GET http://www.asdf.com/example.cgi HTTP/1.1
Cookie: SID=XYZZY8765765vk5ht
...other request headers
Each cookie can have several extra attributes, separated by
semicolons:
Name=Value- this
attribute is compulsory, and more than one is allowed. Both
"
Name" and
"Value" can be any ASCII
string.
expires=DATE- defines the
lifetime of the cookie. Default is the current browser session,
specifying a time in the future means a cookie is stored "in" the
browser. Example:
expires=Sun, 31 Dec 2005 23:59:59 GMT
domain=DOMAIN- an Internet
domain name to which this cookie may be sent. This is normally used
to broaden the range of servers that a cookie will be sent to.
Example:
domain=latrobe.edu.au
path=PATH- defines the
subset of URLs within a domain for which this cookie is valid and
may be sent. Normally used to broaden the range of accesses to a
server (or domain) to which a cookie will be sent. Example:
path=/
Security and Cookies
Cookies have caused a great
deal of debate over the years. The following are some of the
issues:
- Some users don't like the idea that a Web server can write to their
hard disk, however innocuously. In fact, there is no (real) danger
in accepting cookies -- for example, cookies obviously cannot
spread viruses.
- Users worry that cookies might be used to send secret information
about them to a server. In fact, the cookie which is returned is
exactly the same as that which was sent.
- Users are concerned that other Web servers might find out
information about you by reading cookies set by different servers.
In fact, browsers follow very strict rules to ensure that cookies
are only returned to the server (and/or specific CGI program) which
originally sent them -- although, see discussion about the domain
and path attributes in the previous slide.
- Users worry that Web servers can track their "click-through"
behaviour using cookies. In fact, this is true, and is a potential
privacy issue. In response to this concern, virtually all modern
Web browsers offer detailed "preferences" options for how cookies
are to be handled, particularly those sent by "third-party"
advertising sites which supply webpage images.
- All browsers allow the user to turn off acceptance of cookies, and
some users do this. Therefore a session-managed application cannot
rely on the availability of cookies to maintain state information.
Some interesting (although rather dated) information on cookies can be
found at:
Embedding Session Information into the URL
The third way in which the session ID can be passed back and forward
between the server and the browser is to encode it into either the
query string (appended to the ACTION URL in the usual way) or to use a
region of the URL we have not discussed previously: the Extra
Path. The trick here is that all of the links
(including the ACTIONs of FORMs) on every page sent by the server have
to have the session information written into their URL. In the early
days of the Web this was regarded as slow/difficult due to the overhead
of dynamically generating all of this information in real time. This is
no longer an issue.
Most "Real World"™ sites employing URL-encoded session IDs like
to use the query string approach. For example (some bits deleted for
clarity, and with the variable cart interpreted as
the session ID):
http://www.cduniverse.com/browsecat.asp?style=music&cart=236730479
The "Extra Path" is (optional) text in the filepath
section of a URL beyond that required to specify the path to the
executable server-side program. It's commonly used by (for example)
servers which generate dynamic images, to suggest a filename for the
"Save as..." option in browsers, eg:
http://www.asdf.com/images.cgi/Tree042.jpg
In this case, the URL of the image creation program itself is
http://www.asdf.com/images.cgi and
/Tree042.jpg is the extra path information. Whilst
it's perfectly reasonable to use the extra path part of the URL to hold
a session ID, no recent example could be found.
Internet Payment Systems
One of the most difficult issues in Web Commerce is setting up a method
of collecting monetary payment. Since the early days of the Web, this
has attracted a great deal of theorietical interest
(eg, this 1997
PDF report
on Micropayments), but in the end the "traditional" payment
modes (ie, credit card companies) have mostly dominated.
- Approaches to Payment
- Use a third-party payment "clearing house" service, eg
WorldPay,
DirectOne.
- Direct merchant relationship with bank -- uses bank-supplied
"back-end" software.
- "New" approaches, eg PayPal.
- Issues
- Risk of credit-card fraud
- Where is the transaction information stored?
- Cost issues: may be as high as 2.5% to 5% of transaction.
The tutorial for this lecture is
Tutorial #08.
 [Previous Lecture]
[Lecture Index]
[Next Lecture]
[Previous Lecture]
[Lecture Index]
[Next Lecture]
Copyright © 2005 by
Philip Scott,
La Trobe University.
